
Práctica III#
Base de Datos 1.#
Presentación Base de Datos 1.#
Ejercicios de la Base de Datos 1#
Importa las librerías que vas a usar.
Importar el DF.
Mostrar las primeras 5 y las 5 últimas filas del Data.
Cambiar el nombre de al menos 4 columnas y mostrar el DF con las columnas cambiadas.
Filtrar una columna considerando un dato de ella.
Mostrar las cinco primeras filas del DF con los datos filtrados.
Calcular y mostrar las estadísticas descriptivas en una columna.
identificar y mostrar los valores únicos de una columna.
identificar y mostrar la cantidad de veces que aparecen los datos de una de las columnas. Hacer este ejercicio dos veces con dos columnas distintas.
Graficar el dato anterior.
¿Qué es Kaggle?
Base de Datos 2#
Presentación de Base de Datos 2.#
track_name: Nombre de la canción
artista(s)_nombre: Nombre del(los) artista(s) de la canción
artist_count: Número de artistas que contribuyen a la canción
released_year: Año en el que se lanzó la canción
released_month: Mes en el que se lanzó la canción
released_day: Día del mes en el que se lanzó la canción
in_spotify_playlists: Número de listas de reproducción de Spotify en las que se incluye la canción
in_spotify_charts: Presencia y rango de la canción en las listas de Spotify transmisiones: Número total de transmisiones en Spotify
in_apple_playlists: Número de listas de reproducción de Apple Music en las que se incluye la canción
in_apple_charts: Presencia y rango de la canción en las listas de Apple Music
in_deezer_playlists: Número de listas de reproducción de Deezer en las que se incluye la canción
in_deezer_charts: Presencia y rango de la canción en las listas de Deezer
in_shazam_charts: Presencia y rango de la canción en las listas de Shazam
bpm: Latidos por minuto, una medida del tempo de la canción
clave: Clave de la canción
modo: Modo de la canción (mayor o menor)
danceability_%: Porcentaje que indica lo adecuada que es la canción para bailar
valence_%: Positividad del contenido musical de la canción
energy_%: Nivel de energía percibido de la canción
acústica_%: Cantidad de sonido acústico en la canción
instrumentalness_%: Cantidad de contenido instrumental en la canción
liveness_%: Presencia de elementos de actuación en vivo
speechiness_%: Cantidad de palabras habladas en la canción
Ejercicios de la Base de Datos 2.#
Importa las librerías que vas a usar.
Ajustar los datos si fuera necesario.
Importar el DF.
Describir el DF.
Verificar si hay valores nulos.
Realizar algunas de las opciones según corresponda:
Eliminar si hay valores nulos y imprimir el resultado.
Eliminar filas con valores nulos y verificar el resultado.
Eliminar columnas con valores nulos y verificar el resultado.
Rellenar los valores nulos con una cadena específica.
Realizar un gráfico de barra.
Contar el número de canciones por artistas y realizar un gráfico de barras.
Seleccionar algunas características de audio y gráficar un pairplot.
Realizar una matriz de correlación con los datos anteriores.
Graficar con un scatterplot dos relaciones.
Mostrar la media y la desviación estándar de dos valores.
Cambiar el nombre de al menos 4 columnas y mostrar el DF con las columnas cambiadas (al menos las cinco primeras)
Solucionarios#
Warning
Recuerda que los algoritmos que se ofrecen en ambos solucionarios no son respuestas únicas y son solo guías para orientar el aprendizaje.
Solucionario Base de Datos 1#
import pandas as pd
# Cargar el archivo CSV en un DataFrame
df = pd.read_csv('higher_ed_employee_salaries.csv')
# Mostrar las primeras filas del DataFrame
print(df.head())
print(df.tail())
Name School \
0 Don Potter University of Akron
1 Emily Potter The Ohio State University
2 Carol Jean Potter The Ohio State University
3 Kim Potter The Ohio State University
4 Graham Potter Miami University
Job Description \
0 Assistant Lecturer
1 Administrative Assistant 3
2 Associate Professor-Clinical
3 Manager 4, Compliance
4 Building and Grounds Assistant
Department Earnings Year
0 Social Work 2472.00 2019
1 Arts and Sciences | Chemistry and Biochemistry... 48538.02 2022
2 Pediatrics 22722.80 2013
3 Legal Affairs | Compliance 170143.44 2022
4 Assoc VP Housing,Dining,Rec,Bus Svc 3075.20 2012
Name School \
934343 Danielle Noon University of Toledo
934344 Danielle Noon University of Toledo
934345 Kristen Lindsay Noon The Ohio State University
934346 Danielle Noon University of Toledo
934347 Kevin R Noon Bowling Green State University
Job Description Department Earnings Year
934343 Medical Assistant OP-Clinic-Orthopedic 31659.43 2021
934344 Patient Registration Spec Registration 7974.25 2019
934345 Assistant Professor-Clinical Anesthesiology 243033.56 2018
934346 Medical Assistant OP-Clinic-Orthopedic 37642.16 2022
934347 Asst Men's Basketbal Coach Basketball - Men 103630.58 2022
# Cambiar los nombres de las columnas
nuevos_nombres = {
'Name': 'Nombre',
'School': 'Escuela',
'Job Description': 'Trabajo',
'Department': 'Departamento',
'Earnings': 'Ganancias',
'Year': 'Año'
}
df = df.rename(columns=nuevos_nombres)
# Mostrar solo los nombres de las columnas cambiadas
print(df.columns)
Index(['Nombre', 'Escuela', 'Trabajo', 'Departamento', 'Ganancias', 'Año'], dtype='object')
# Filtrar datos por año (por ejemplo, 2019)
df_2019 = df[df['Año'] == 2019]
# Mostrar las primeras filas del DataFrame filtrado
print(df_2019.head())
Nombre Escuela Trabajo \
0 Don Potter University of Akron Assistant Lecturer
35 Devante Potter The Ohio State University Research Assistant 1-B/H
36 Ana Potter The Ohio State University Patient Care Associate
40 Carol Potter The Ohio State University Associate Professor-Clinical
68 Luke Potter The Ohio State University Patient Care Associate
Departamento Ganancias Año
0 Social Work 2472.00 2019
35 Chemistry and Biochemistry 20493.20 2019
36 University Hospitals 6583.86 2019
40 Pediatrics 51060.36 2019
68 Cancer Hosp & Research Instit 6784.69 2019
# Calcular estadísticas descriptivas de las ganancias
earnings_stats = df['Ganancias'].describe()
# Mostrar estadísticas descriptivas
print(earnings_stats)
count 9.246730e+05
mean 5.465913e+04
std 6.137398e+04
min 2.000000e-02
25% 2.024923e+04
50% 4.452501e+04
75% 7.099997e+04
max 8.021377e+06
Name: Ganancias, dtype: float64
# Identificar las escuelas únicas
escuelas_unicas = df['Escuela'].unique()
# Mostrar las escuelas únicas
print("Escuelas únicas:")
for escuela in escuelas_unicas:
print(escuela)
Escuelas únicas:
University of Akron
The Ohio State University
Miami University
Bowling Green State University
Central State University
Ohio University
Youngstown State University
Kent State University
University Of Cincinnati
Wright State University
University of Toledo
Shawnee State University
Cleveland State University
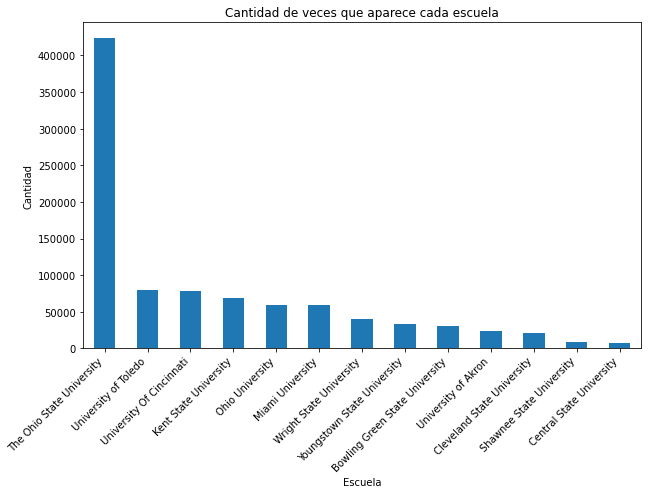
# Contar la cantidad de veces que aparece cada escuela
conteo_escuelas = df['Escuela'].value_counts()
# Mostrar el conteo de escuelas
print("Cantidad de veces que aparece cada escuela:")
print(conteo_escuelas)
Cantidad de veces que aparece cada escuela:
The Ohio State University 424050
University of Toledo 79777
University Of Cincinnati 79021
Kent State University 68338
Ohio University 59852
Miami University 58712
Wright State University 40215
Youngstown State University 32891
Bowling Green State University 31119
University of Akron 24101
Cleveland State University 20876
Shawnee State University 8362
Central State University 7034
Name: Escuela, dtype: int64
import matplotlib.pyplot as plt
# Graficar el conteo de escuelas
plt.figure(figsize=(10, 6))
conteo_escuelas.plot(kind='bar')
plt.title('Cantidad de veces que aparece cada escuela')
plt.xlabel('Escuela')
plt.ylabel('Cantidad')
plt.xticks(rotation=45, ha='right')
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]),
[Text(0, 0, 'The Ohio State University'),
Text(1, 0, 'University of Toledo'),
Text(2, 0, 'University Of Cincinnati'),
Text(3, 0, 'Kent State University'),
Text(4, 0, 'Ohio University'),
Text(5, 0, 'Miami University'),
Text(6, 0, 'Wright State University'),
Text(7, 0, 'Youngstown State University'),
Text(8, 0, 'Bowling Green State University'),
Text(9, 0, 'University of Akron'),
Text(10, 0, 'Cleveland State University'),
Text(11, 0, 'Shawnee State University'),
Text(12, 0, 'Central State University')])
# Contar la cantidad de veces que aparece cada Trabajo.
conteo_escuelas = df['Trabajo'].value_counts()
# Mostrar el conteo de escuelas
print("Cantidad de veces que aparece cada Trabajo:")
print(conteo_escuelas)
Cantidad de veces que aparece cada Trabajo:
Professor 28204
Associate Professor 24831
Assistant Professor 18684
Staff Nurse-B 18399
Lecturer 15439
...
Manager 3, Nursing Education 1
Assoc Professor - Educator CEAS - Mechanical Eng Tech 1
Business Officer College of Allied Health Sciences 1
QM Instructional Designer & Master Reviewer 1
Assoc Head Mens BB Coach 1
Name: Trabajo, Length: 38679, dtype: int64
Solucionario de Base de Datos 2.#
import pandas as pd
# Leer el archivo en modo binario y decodificar manualmente
with open('spotify-2023.csv', 'rb') as f:
content = f.read()
try:
decoded_content = content.decode('utf-8')
except UnicodeDecodeError:
decoded_content = content.decode('latin-1') # O cualquier otra codificación que sospeches
# Guardar el contenido decodificado en un nuevo archivo temporal
with open('spotify-2023-temp.csv', 'w', encoding='utf-8') as f:
f.write(decoded_content)
# Cargar los datos desde el archivo temporal CSV
df = pd.read_csv('spotify-2023-temp.csv')
# Mostrar las primeras filas del DataFrame
print(df.head())
print(df.tail())
track_name artist(s)_name artist_count \
0 Seven (feat. Latto) (Explicit Ver.) Latto, Jung Kook 2
1 LALA Myke Towers 1
2 vampire Olivia Rodrigo 1
3 Cruel Summer Taylor Swift 1
4 WHERE SHE GOES Bad Bunny 1
released_year released_month released_day in_spotify_playlists \
0 2023 7 14 553
1 2023 3 23 1474
2 2023 6 30 1397
3 2019 8 23 7858
4 2023 5 18 3133
in_spotify_charts streams in_apple_playlists ... bpm key mode \
0 147 141381703 43 ... 125 B Major
1 48 133716286 48 ... 92 C# Major
2 113 140003974 94 ... 138 F Major
3 100 800840817 116 ... 170 A Major
4 50 303236322 84 ... 144 A Minor
danceability_% valence_% energy_% acousticness_% instrumentalness_% \
0 80 89 83 31 0
1 71 61 74 7 0
2 51 32 53 17 0
3 55 58 72 11 0
4 65 23 80 14 63
liveness_% speechiness_%
0 8 4
1 10 4
2 31 6
3 11 15
4 11 6
[5 rows x 24 columns]
track_name artist(s)_name artist_count \
948 My Mind & Me Selena Gomez 1
949 Bigger Than The Whole Sky Taylor Swift 1
950 A Veces (feat. Feid) Feid, Paulo Londra 2
951 En La De Ella Feid, Sech, Jhayco 3
952 Alone Burna Boy 1
released_year released_month released_day in_spotify_playlists \
948 2022 11 3 953
949 2022 10 21 1180
950 2022 11 3 573
951 2022 10 20 1320
952 2022 11 4 782
in_spotify_charts streams in_apple_playlists ... bpm key mode \
948 0 91473363 61 ... 144 A Major
949 0 121871870 4 ... 166 F# Major
950 0 73513683 2 ... 92 C# Major
951 0 133895612 29 ... 97 C# Major
952 2 96007391 27 ... 90 E Minor
danceability_% valence_% energy_% acousticness_% instrumentalness_% \
948 60 24 39 57 0
949 42 7 24 83 1
950 80 81 67 4 0
951 82 67 77 8 0
952 61 32 67 15 0
liveness_% speechiness_%
948 8 3
949 12 6
950 8 6
951 12 5
952 11 5
[5 rows x 24 columns]
# Describir el DataFrame para obtener estadísticas descriptivas
print(df.describe())
# Verificar si hay valores nulos en el DataFrame
print(df.isnull().sum())
artist_count released_year released_month released_day \
count 953.000000 953.000000 953.000000 953.000000
mean 1.556139 2018.238195 6.033578 13.930745
std 0.893044 11.116218 3.566435 9.201949
min 1.000000 1930.000000 1.000000 1.000000
25% 1.000000 2020.000000 3.000000 6.000000
50% 1.000000 2022.000000 6.000000 13.000000
75% 2.000000 2022.000000 9.000000 22.000000
max 8.000000 2023.000000 12.000000 31.000000
in_spotify_playlists in_spotify_charts in_apple_playlists \
count 953.000000 953.000000 953.000000
mean 5200.124869 12.009444 67.812172
std 7897.608990 19.575992 86.441493
min 31.000000 0.000000 0.000000
25% 875.000000 0.000000 13.000000
50% 2224.000000 3.000000 34.000000
75% 5542.000000 16.000000 88.000000
max 52898.000000 147.000000 672.000000
in_apple_charts in_deezer_charts bpm danceability_% \
count 953.000000 953.000000 953.000000 953.00000
mean 51.908709 2.666317 122.540399 66.96957
std 50.630241 6.035599 28.057802 14.63061
min 0.000000 0.000000 65.000000 23.00000
25% 7.000000 0.000000 100.000000 57.00000
50% 38.000000 0.000000 121.000000 69.00000
75% 87.000000 2.000000 140.000000 78.00000
max 275.000000 58.000000 206.000000 96.00000
valence_% energy_% acousticness_% instrumentalness_% liveness_% \
count 953.000000 953.000000 953.000000 953.000000 953.000000
mean 51.431270 64.279119 27.057712 1.581322 18.213012
std 23.480632 16.550526 25.996077 8.409800 13.711223
min 4.000000 9.000000 0.000000 0.000000 3.000000
25% 32.000000 53.000000 6.000000 0.000000 10.000000
50% 51.000000 66.000000 18.000000 0.000000 12.000000
75% 70.000000 77.000000 43.000000 0.000000 24.000000
max 97.000000 97.000000 97.000000 91.000000 97.000000
speechiness_%
count 953.000000
mean 10.131165
std 9.912888
min 2.000000
25% 4.000000
50% 6.000000
75% 11.000000
max 64.000000
track_name 0
artist(s)_name 0
artist_count 0
released_year 0
released_month 0
released_day 0
in_spotify_playlists 0
in_spotify_charts 0
streams 0
in_apple_playlists 0
in_apple_charts 0
in_deezer_playlists 0
in_deezer_charts 0
in_shazam_charts 50
bpm 0
key 95
mode 0
danceability_% 0
valence_% 0
energy_% 0
acousticness_% 0
instrumentalness_% 0
liveness_% 0
speechiness_% 0
dtype: int64
# Eliminar columnas que contienen valores nulos
df_sin_nulos_columnas = df.dropna(axis=1)
# Verificar el resultado
print(df_sin_nulos_columnas.isnull().sum())
track_name 0
artist(s)_name 0
artist_count 0
released_year 0
released_month 0
released_day 0
in_spotify_playlists 0
in_spotify_charts 0
streams 0
in_apple_playlists 0
in_apple_charts 0
in_deezer_playlists 0
in_deezer_charts 0
bpm 0
mode 0
danceability_% 0
valence_% 0
energy_% 0
acousticness_% 0
instrumentalness_% 0
liveness_% 0
speechiness_% 0
dtype: int64
# Eliminar filas que contienen valores nulos
df_sin_nulos = df.dropna()
# Verificar el resultado
print(df_sin_nulos.isnull().sum())
track_name 0
artist(s)_name 0
artist_count 0
released_year 0
released_month 0
released_day 0
in_spotify_playlists 0
in_spotify_charts 0
streams 0
in_apple_playlists 0
in_apple_charts 0
in_deezer_playlists 0
in_deezer_charts 0
in_shazam_charts 0
bpm 0
key 0
mode 0
danceability_% 0
valence_% 0
energy_% 0
acousticness_% 0
instrumentalness_% 0
liveness_% 0
speechiness_% 0
dtype: int64
# Eliminar columnas que contienen valores nulos
df_sin_nulos_columnas = df.dropna(axis=1)
# Verificar el resultado
print(df_sin_nulos_columnas.isnull().sum())
track_name 0
artist(s)_name 0
artist_count 0
released_year 0
released_month 0
released_day 0
in_spotify_playlists 0
in_spotify_charts 0
streams 0
in_apple_playlists 0
in_apple_charts 0
in_deezer_playlists 0
in_deezer_charts 0
bpm 0
mode 0
danceability_% 0
valence_% 0
energy_% 0
acousticness_% 0
instrumentalness_% 0
liveness_% 0
speechiness_% 0
dtype: int64
# Rellenar los valores nulos con 0
df_relleno_cero = df.fillna(0)
# Verificar el resultado
print(df_relleno_cero.isnull().sum())
track_name 0
artist(s)_name 0
artist_count 0
released_year 0
released_month 0
released_day 0
in_spotify_playlists 0
in_spotify_charts 0
streams 0
in_apple_playlists 0
in_apple_charts 0
in_deezer_playlists 0
in_deezer_charts 0
in_shazam_charts 0
bpm 0
key 0
mode 0
danceability_% 0
valence_% 0
energy_% 0
acousticness_% 0
instrumentalness_% 0
liveness_% 0
speechiness_% 0
dtype: int64
# Rellenar los valores nulos con una cadena específica
df_relleno_texto = df.fillna('Desconocido')
# Verificar el resultado
print(df_relleno_texto.isnull().sum())
track_name 0
artist(s)_name 0
artist_count 0
released_year 0
released_month 0
released_day 0
in_spotify_playlists 0
in_spotify_charts 0
streams 0
in_apple_playlists 0
in_apple_charts 0
in_deezer_playlists 0
in_deezer_charts 0
in_shazam_charts 0
bpm 0
key 0
mode 0
danceability_% 0
valence_% 0
energy_% 0
acousticness_% 0
instrumentalness_% 0
liveness_% 0
speechiness_% 0
dtype: int64
# Rellenar los valores nulos con la media de cada columna
df_relleno_media = df.apply(lambda x: x.fillna(x.mean()) if x.dtype.kind in 'biufc' else x)
# Verificar el resultado
print(df_relleno_media.isnull().sum())
track_name 0
artist(s)_name 0
artist_count 0
released_year 0
released_month 0
released_day 0
in_spotify_playlists 0
in_spotify_charts 0
streams 0
in_apple_playlists 0
in_apple_charts 0
in_deezer_playlists 0
in_deezer_charts 0
in_shazam_charts 50
bpm 0
key 95
mode 0
danceability_% 0
valence_% 0
energy_% 0
acousticness_% 0
instrumentalness_% 0
liveness_% 0
speechiness_% 0
dtype: int64
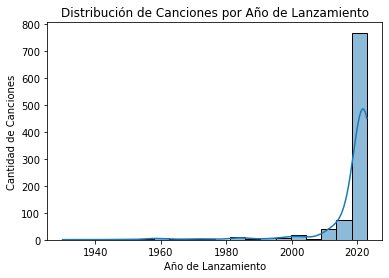
import seaborn as sns
import matplotlib.pyplot as plt
# Plotear la distribución del año de lanzamiento
sns.histplot(df['released_year'], bins=20, kde=True)
plt.title('Distribución de Canciones por Año de Lanzamiento')
plt.xlabel('Año de Lanzamiento')
plt.ylabel('Cantidad de Canciones')
plt.show()
# Contar el número de canciones por artista
top_artists = df['artist(s)_name'].value_counts().head(10)
# Plotear los 10 artistas con más canciones
sns.barplot(x=top_artists.values, y=top_artists.index)
plt.title('Top 10 Artistas con Más Canciones en el Dataset')
plt.xlabel('Número de Canciones')
plt.ylabel('Artista')
plt.show()

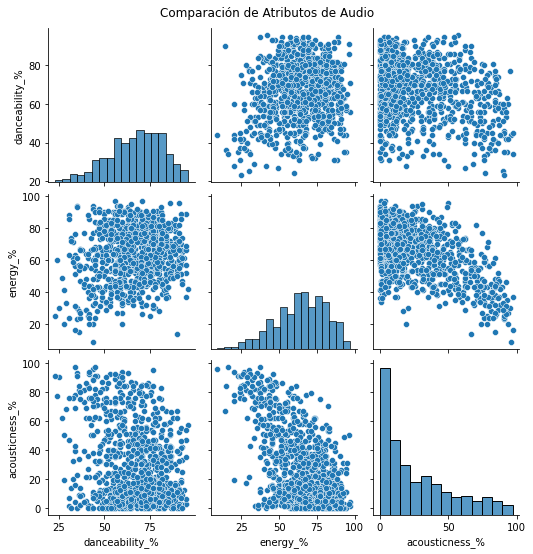
# Seleccionar algunas características de audio
audio_features = ['danceability_%', 'energy_%', 'acousticness_%']
# Plotear un parplot para comparar estas características
sns.pairplot(df[audio_features])
plt.suptitle('Comparación de Atributos de Audio', y=1.02)
plt.show()
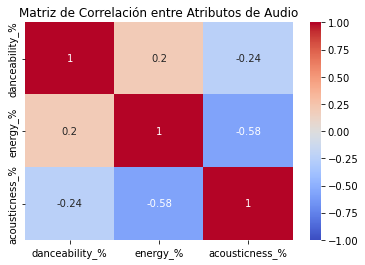
import numpy as np
# Calcular la matriz de correlación
corr = df[audio_features].corr()
# Crear un mapa de calor de la matriz de correlación
sns.heatmap(corr, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Matriz de Correlación entre Atributos de Audio')
plt.show()
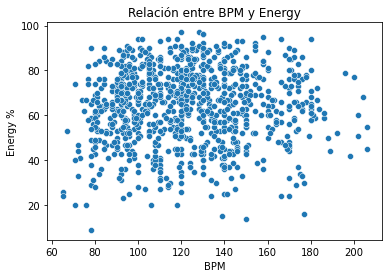
# Plotear la relación entre BPM y energy
sns.scatterplot(x='bpm', y='energy_%', data=df)
plt.title('Relación entre BPM y Energy')
plt.xlabel('BPM')
plt.ylabel('Energy %')
plt.show()
import numpy as np
# Calcular la media y desviación estándar de los BPM
bpm_mean = np.mean(df['bpm'])
bpm_std = np.std(df['bpm'])
print(f'Media de BPM: {bpm_mean}')
print(f'Desviación Estándar de BPM: {bpm_std}')
# Calcular la media y desviación estándar de la energía
energy_mean = np.mean(df['energy_%'])
energy_std = np.std(df['energy_%'])
print(f'Media de Energy %: {energy_mean}')
print(f'Desviación Estándar de Energy %: {energy_std}')
Media de BPM: 122.54039874081847
Desviación Estándar de BPM: 28.04307686714831
Media de Energy %: 64.2791185729276
Desviación Estándar de Energy %: 16.54184031690203
# Mostrar las primeras filas del DataFrame original
print("Columnas originales:", df.columns)
# Renombrar las columnas
df.columns = [
'Nombre', 'Artista', 'Artista_Contribuyentes', 'Año_lanzamiento', "mes_lanzamiento",
'Día_lanzamiento', 'Listas_Spotify', 'Transmisiones_Spotify', 'Listas_Apple',
'Presencia_rango_Apple', "Listas_Deezer", 'Presencia_rango_Deezer', 'Listas_Shazam', 'Anchura_Pixel',
'Latidos', 'Clave', 'Modo', '%_Baile', 'Positividad', '%_energía', '%_sonido_acústico',
'%_contenido_instrumental', '%_actuación_vivo', '%_palabras_habladas',
]
# Mostrar las primeras filas del DataFrame con los nuevos nombres de las columnas
print("Nuevas columnas:", df.columns)
print(df.head())
Columnas originales: Index(['track_name', 'artist(s)_name', 'artist_count', 'released_year',
'released_month', 'released_day', 'in_spotify_playlists',
'in_spotify_charts', 'streams', 'in_apple_playlists', 'in_apple_charts',
'in_deezer_playlists', 'in_deezer_charts', 'in_shazam_charts', 'bpm',
'key', 'mode', 'danceability_%', 'valence_%', 'energy_%',
'acousticness_%', 'instrumentalness_%', 'liveness_%', 'speechiness_%'],
dtype='object')
Nuevas columnas: Index(['Nombre', 'Artista', 'Artista_Contribuyentes', 'Año_lanzamiento',
'mes_lanzamiento', 'Día_lanzamiento', 'Listas_Spotify',
'Transmisiones_Spotify', 'Listas_Apple', 'Presencia_rango_Apple',
'Listas_Deezer', 'Presencia_rango_Deezer', 'Listas_Shazam',
'Anchura_Pixel', 'Latidos', 'Clave', 'Modo', '%_Baile', 'Positividad',
'%_energía', '%_sonido_acústico', '%_contenido_instrumental',
'%_actuación_vivo', '%_palabras_habladas'],
dtype='object')
Nombre Artista \
0 Seven (feat. Latto) (Explicit Ver.) Latto, Jung Kook
1 LALA Myke Towers
2 vampire Olivia Rodrigo
3 Cruel Summer Taylor Swift
4 WHERE SHE GOES Bad Bunny
Artista_Contribuyentes Año_lanzamiento mes_lanzamiento Día_lanzamiento \
0 2 2023 7 14
1 1 2023 3 23
2 1 2023 6 30
3 1 2019 8 23
4 1 2023 5 18
Listas_Spotify Transmisiones_Spotify Listas_Apple Presencia_rango_Apple \
0 553 147 141381703 43
1 1474 48 133716286 48
2 1397 113 140003974 94
3 7858 100 800840817 116
4 3133 50 303236322 84
... Latidos Clave Modo %_Baile Positividad %_energía %_sonido_acústico \
0 ... 125 B Major 80 89 83 31
1 ... 92 C# Major 71 61 74 7
2 ... 138 F Major 51 32 53 17
3 ... 170 A Major 55 58 72 11
4 ... 144 A Minor 65 23 80 14
%_contenido_instrumental %_actuación_vivo %_palabras_habladas
0 0 8 4
1 0 10 4
2 0 31 6
3 0 11 15
4 63 11 6
[5 rows x 24 columns]