
Procesamiento Lenguaje Natural (NLP) I#
¿Qué es el NLP?#
¿Cuando se origina?
El campo del procesamiento del lenguaje natural comenzó en la década de 1940, después de la Segunda Guerra Mundial. En ese tiempo, se reconoció la importancia de la traducción de un idioma a otro y se esperaba crear una máquina que pudiera hacer esta traducción automáticamente.
En el NLP o Natural Language Processing se traduce a procesamiento del lenguaje natural y se refiere a la rama de la informática, más concretamente la rama de la inteligencia artificial que se encarga de dar a los ordenadores la capacidad de entender texto de la misma forma que los seres humanos.
Combina lingüística computacional el modelo de lenguaje humano basado en reglas con modelos estadísticos de aprendizaje automático y de aprendizaje profundo. Todas estas tecnologías permiten que los ordenadores procesen el lenguaje humano para que parezca que comprenden, generan y responden de manera natural y coherente, como si tuvieran una comprensión real del significado y contexto detrás de las palabras y frases. A continuación se presenta una imagen con los principales hitos de la Genesis y Evolución de NLP en (https://commtelnetworks.com)
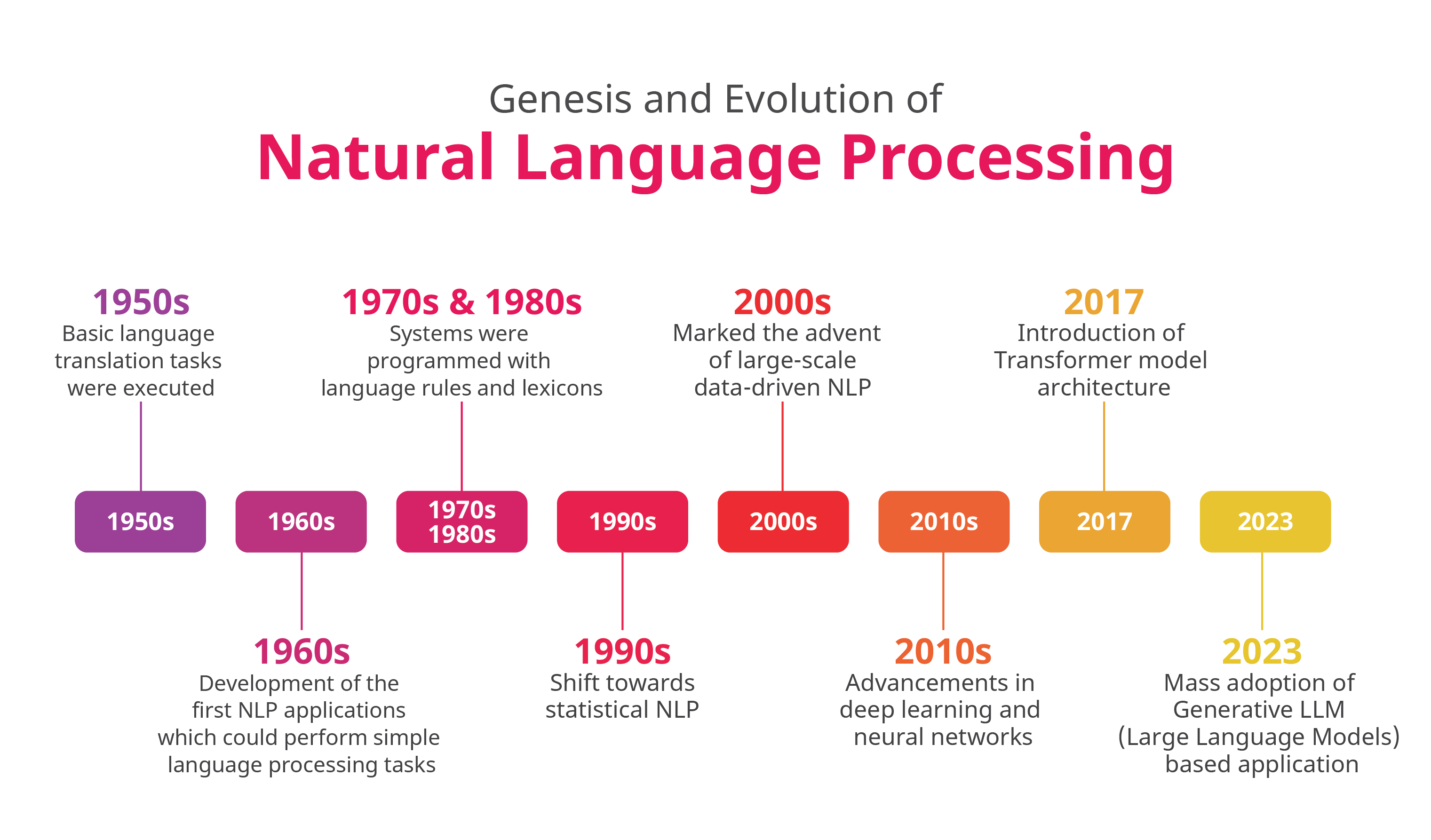
Fig. 5 Genesis y Evolución de NLP#
Librerías para NLP#
Librería |
Descripción |
|---|---|
NLTK |
Es una biblioteca que admite tareas como clasificación, etiquetado, derivación, análisis y razonamiento semántico. |
Spacy |
Permite crear aplicaciones que pueden procesar y comprender grandes volúmenes de texto y admite tokenización para más de 49 idiomas. |
Gensim |
Logra implementaciones multinúcleo eficientes de algoritmos como el análisis semántico latente (LSA) y la asignación de Dirichlet latente (LDA). |
Pattern |
Es una biblioteca multipropósito que puede manejar NLP, minería de datos, análisis de redes, aprendizaje automático y visualización |
NLTK o Kit de Herramientas de Lenguaje Natural#
¿Cuando se origina?
NLTK fue desarrollado en la Universidad de Pensilvania por Steven Bird y Edward Loper a finales de la década de 1990. Inicialmente se creó como una plataforma para la enseñanza e investigación en lingüística computacional y procesamiento del lenguaje natural (NLP). Con el paso de los años, NLTK ha evolucionado hasta convertirse en una biblioteca indispensable para tareas relacionadas con el lenguaje en los dominios de inteligencia artificial, aprendizaje automático y ciencia de datos.
Flujo o Pipeline de NLP#
¿Qué es el Pipeline?
Se refiere a una secuencia de etapas o tareas que se aplican secuencialmente al procesar un texto o documento de texto. Cada etapa de la pipeline tiene un propósito específico y procesa el texto de alguna manera antes de pasar los resultados a la siguiente etapa. Las pipelines de NLP son fundamentales para realizar tareas de análisis de texto y extracción de información de manera sistemática y estructurada.
A continuación se presenta una descripción general de las etapas comunes en un pipeline de PNL:
- Recolección de Datos:Obtención de datos de texto desde diversas fuentes, como bases de datos, documentos, sitios web, redes sociales, etc.
- Preprocesamiento de Datos:
- Limpieza de Datos: Eliminación de caracteres no deseados, corrección de errores tipográficos, manejo de texto en mayúsculas y minúsculas.
- Tokenización: División del texto en unidades más pequeñas, como palabras o frases.
- Eliminación de Stop Words: Eliminación de palabras comunes que no aportan mucho significado (ej. "el", "la", "de" en español).
- Normalización: Convertir palabras a su forma base o raíz, por ejemplo, usando lematización o stemming.
- Representación de Texto(Codificación): Transformar texto en una representación numérica adecuada para su procesamiento. Métodos comunes incluyen Bag of Words, TF-IDF, y embeddings (ej. Word2Vec, GloVe, BERT).
- Análisis Sintáctico:
- Etiquetado de Partes del Discurso (POS Tagging): Asignar etiquetas gramaticales a cada token (ej. sustantivo, verbo).
- Reconocimiento de Entidades Nombradas (NER): Identificar y clasificar entidades mencionadas en el texto (ej. nombres de personas, lugares, organizaciones).
- Análisis Semántico:
- Desambiguación de Palabras: Determinar el significado correcto de una palabra que tiene múltiples sentidos en un contexto específico.
- Extracción de Relaciones: Identificar relaciones entre entidades en el texto.
- Modelado y Análisis:
- Análisis de Sentimientos: Determinar la actitud o emoción expresada en el texto.
- Clasificación de Texto: Asignar categorías o etiquetas a fragmentos de texto.
- Generación de Texto: Crear texto nuevo basado en el aprendizaje de un corpus existente.
- Evaluación y Mejora:
- Evaluar los resultados del análisis utilizando métricas adecuadas (precisión, recall, F1-score).
- Ajustar y mejorar los modelos basándose en la evaluación.
- Implementación del modelo en un entorno de producción para su uso en aplicaciones reales.